Launch Your Streaming Service Faster
Carrier-grade video infrastructure for telecom operators and content owners. From source to screen, fully integrated.
Trusted by Leading Operators
Powering streaming services for telecom providers worldwide
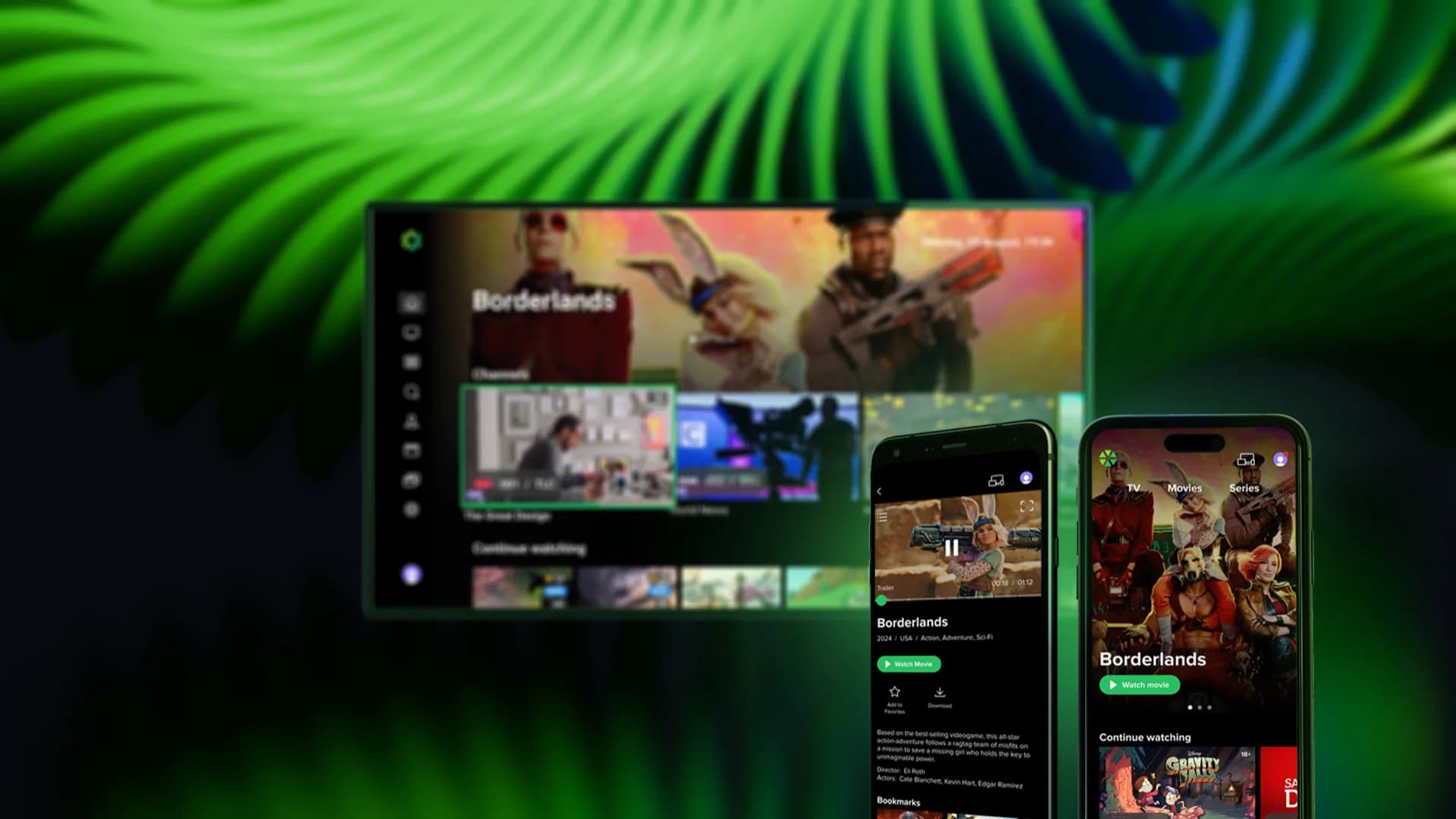
Your content.
Every screen. One platform.
See how it all works togetherService Delivery Platform
Complete OTT/IPTV middleware with multi-screen support, advanced DRM protection, and flexible monetization. Power your streaming business from content to customer.
Learn more
Content Delivery
High-performance media server and CDN solution. Advanced transcoding, encryption, and intelligent routing for optimal streaming performance worldwide.
Learn more
Monitoring & Analytics
Real-time quality monitoring and analytics system. Track performance metrics, identify issues before they impact users, and optimize your infrastructure.
Learn more
Client Applications
Native multi-screen applications for Smart TV, mobile, web, and STB. Consistent user experience across all devices with customizable UI and branding.
Learn more
Built for carrier-grade scale
Global Infrastructure
Multi-CDN support with intelligent routing, failover protection, and low-latency delivery worldwide.
Explore SmartMEDIAContent Protection
Full content protection stack supporting all major platforms. Meet studio requirements and protect your investment.
Explore SmartMEDIAScalable Architecture
Cloud-native design supporting millions of concurrent users with automatic scaling and load balancing.
Learn about SaaSReal-time Analytics
Comprehensive monitoring and reporting with detailed QoS/QoE metrics and user behavior insights.
Explore SmartCAREMulti-Platform Support
Native applications for web, mobile, smart TV, and STB with consistent user experience.
Explore appsFlexible Monetization
Support for SVOD, TVOD, AVOD, and hybrid models with integrated payment processing.
Explore SmartTUBEReady to transform
your streaming business?
A quick conversation to understand your goals and tailor our approach.